Over the last decade, video technology has raced forward faster than most network cables can comfortably carry. Resolutions have climbed from HD to 4K, are moving toward 8K, and are expanding into entirely new worlds such as augmented reality (AR), virtual reality (VR), and mixed reality. These formats demand extremely high-quality visuals, high frame rates, and very low latency. At the same time, audiences expect instant playback on phones, TVs, and headsets anywhere in the world.
To make all this possible, video compression is essential. Modern codecs such as H.264 once dominated, but newer standards such as HEVC (H.265), AV1, and the emerging VVC are being adopted to deliver better visual quality at lower bitrates. These codecs are designed to squeeze as much visual information as possible into the smallest possible data stream.

However, even the most advanced codecs face hard limits. Video files remain large, networks remain imperfect, and visual quality can drop when compression becomes aggressive. That is why companies are now combining traditional compression with artificial intelligence, machine learning, and post-processing techniques to push quality even further.
Netflix uses content-adaptive encoding and quality metrics like VMAF to tune bitrate to the type of scene and device. YouTube experiments with AI-enhanced upscaling and adaptive streaming at massive scale. Nvidia offers technologies such as RTX Video Super Resolution that clean and sharpen video on the GPU side to improve low-resolution streams.
Each company is attacking the same basic problem from different directions.
Amazon also enters with a newly published patent application focused on AI-based video enhancement. It does not try to replace codecs like HEVC or AV1, but instead addresses a specific niche problem inside the broader ecosystem.
The Problem with Compressed Videos
Even with modern codecs, video compression removes detail. Fine textures such as hair, grass, text edges, or animated lines often become blurry or blocky when bitrates drop. This loss is not random, it is the result of compression algorithms deliberately throwing away information to reduce file size.
The problem becomes more visible when:
- the content is highly detailed
- the resolution is high (4K or above)
- the display is large (TVs, projectors, headsets)
- motion is fast, such as live sports or gaming
- Limited Lighting
The patent focuses on what happens after decoding compressed video. In a normal pipeline, video is compressed by the encoder, sent over the network, decoded on the device, and then displayed. Once the information is lost during compression, it usually stays lost.
Amazon’s patent proposes a system in which an AI engine sits after decoding and tries to reconstruct the fine details that compression removed, without increasing the transmitted bitrate. This is a supplemental enhancement step rather than a full replacement for codecs.
In simple terms, the niche problem is:
How can the system restore sharpness and detail to already-compressed video after it arrives at the user’s device?
This is different from traditional compression research because it works after video is delivered rather than during encoding only.
Why this challenge matters to Amazon
The challenge matters to every streaming platform, but it is particularly important for Amazon for two reasons.
First, Amazon operates its own consumer streaming services:
- Prime Video for movies and shows
- Freevee for ad-supported video
- Twitch for live streaming and gaming
Video quality strongly affects user experience. Higher quality improves:
- watch time
- user satisfaction
- perceived brand value
- competitiveness with Netflix, Disney+, and YouTube
However, increasing bitrate also increases cost. Bandwidth and storage are among the largest expenses for streaming platforms at global scale. Being able to deliver high-quality video at lower bitrates directly improves margins.
Second, Amazon is not only a streaming platform but also a cloud service provider. Its AWS infrastructure hosts and powers many third-party streaming platforms and content delivery services. That means video technology is both:
- a consumer product, and
- a business-to-business service
Better AI-based enhancement tools can be integrated into AWS media services such as transcoding, delivery, and edge processing. That strengthens Amazon’s position not only against other streaming companies, but also against other cloud providers like Google Cloud and Microsoft Azure.
For Amazon, solving this challenge is therefore strategic on multiple levels: customer experience, cost optimization, infrastructure leadership, and cloud competitiveness.
Amazon’s Solution to Enhance Compressed Video
Amazon’s patent describes a system designed to sit quietly at the end of the traditional video pipeline and improve the quality of already-compressed video. Rather than replacing existing codecs such as HEVC, AV1, or VVC, the approach works after decoding and uses an AI-driven enhancement engine to restore detail, reduce artifacts, and, when needed, upscale resolution. The process is a multiple step approach as described below.
Step 1: Understanding where the enhancement engine sits
In a normal streaming pipeline, the process is straightforward: the video is compressed by an encoder, transmitted, decoded on the device, and then displayed. Amazon inserts a new intelligent step between decoding and display. The decoded video first passes through an AI enhancement engine that attempts to reconstruct lost details.
This overall flow is best illustrated in the Figure.
This figure shows the entire concept at a glance. Everything else in the patent explains what happens inside that post-processing box.
Step 2: Standard encoding and decoding still do the main transport work
Before enhancement begins, video still travels through traditional codecs. The patent explicitly outlines conventional encoding and decoding blocks, reinforcing that its novelty lies after this process rather than replacing it.
Figure 4 shows the internal structure of a typical encoder, including motion estimation, transforms, quantization, and entropy coding.
Where to include image: include Figure 4 after the paragraph explaining compression; it helps non-experts see the complexity of the “normal” codec.
On the playback side, Figure 6 represents the decoder reconstructing the compressed video frames before they reach the enhancement engine. This is exactly where Amazon’s model plugs in.
Where to include image: place Figure 6 directly after introducing the decode stage, to clearly show where enhancement begins.
Step 3: Feeding decoded frames into an AI enhancement engine
Once the decoder outputs a frame, it is already degraded compared to the original source. Compression has removed texture, fine detail, and sometimes stability in edges or gradients. The enhancement engine receives these decoded frames as inputs.
The goal of the engine is not to invent a completely new picture. Instead, it attempts to predict the missing details that compression removed and add them back. This is done using a neural network trained on pairs of:
- high-quality reference video, and
- compressed versions of the same video.
Through training, the model learns typical compression artifacts and how to reverse them.
Step 4: Multi-scale processing – looking at the picture at different zoom levels
A central feature of Amazon’s design is multi-scale processing. The AI does not analyze each frame at only one resolution. Instead, it creates several scaled versions of the image and processes them in parallel.
In practice, the system looks at:
- the full-resolution image for sharp edges and fine textures
- half-resolution for medium structures
- quarter-resolution for broad shapes and smooth gradients
This design allows the network to see both tiny details (hair, text, grass) and global structure (faces, sky, large objects) simultaneously.
The figure below shows a two-scale system with full-resolution and half-resolution branches.
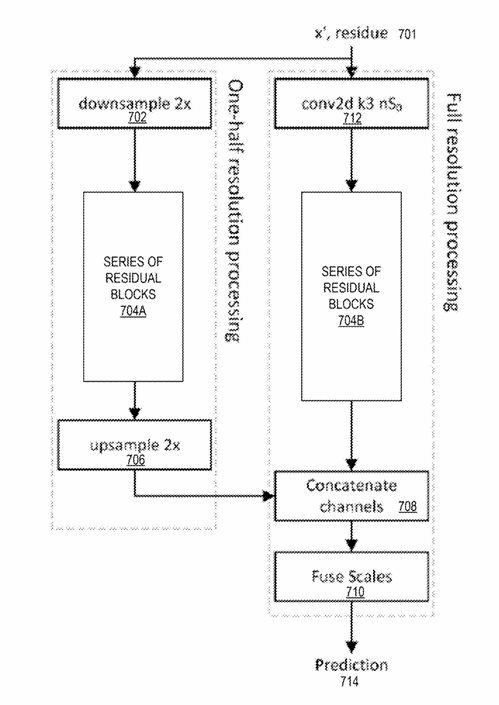
The key benefit: by blending multiple zoom levels, the model can sharpen without overshooting and smooth without blurring.
Step 5: Residual learning – predicting only what is missing
The enhancement engine uses a method known as residual learning. Instead of predicting the full enhanced frame, the model predicts only the difference between the decoded frame and the desired high-quality frame.
The final output is simply:
decoded frame
- predicted residual
= enhanced frame
This approach has two major advantages:
- the model does not “fight” with the existing decoded image
- the network learns compression errors directly rather than re-creating the whole picture
Residual learning also reduces hallucination of unrealistic detail, something that pure generative models often struggle with.
Step 6: The neural network’s internal building blocks
Inside the enhancement engine are many stacked units known as residual blocks. Each residual block contains:
- a convolution layer
- an activation function (such as ReLU or sigmoid)
- another convolution layer
- a skip connection adding the original input back to the output
This structure is shown clearly in Figure 12 of the patent.
Other Figures illustrate activation functions such as ReLU and sigmoid, which introduce non-linear behavior. These nonlinearities are what allow the network to handle complex patterns like ringing, blocking, and subtle texture restoration.
These alternatives allow the model to balance smoothing, sharpening, and artifact removal differently for different content types.
Step 7: Combining information from every scale
After each resolution branch has processed the frame, the model must combine all of those results. This process is called scale fusion.
First, outputs from the multiple scales are concatenated channel-wise.
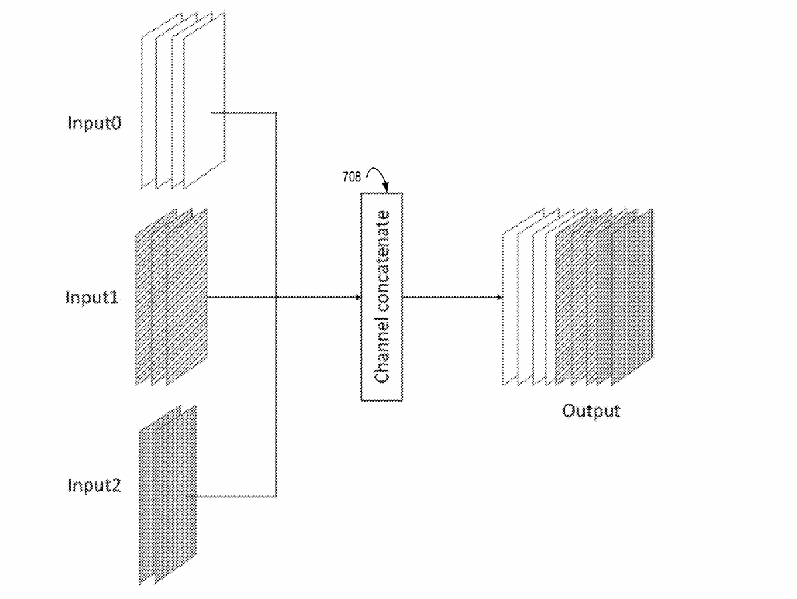
Then, specialized fusion modules—shown in Figures 17, 18, and 19—merge the information from all scales into one consistent enhancement signal.
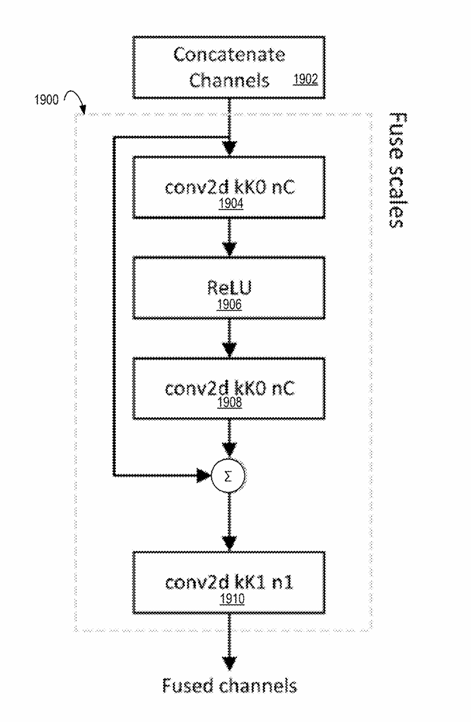
In simple terms, fusion allows the model to answer questions like:
- how should fine texture align with large shapes?
- where should edges be sharpened but noise avoided?
- when should smooth areas remain smooth?
The fused output becomes the predicted residual that gets added to the decoded frame.
Step 8: Producing the final enhanced video frame
Once fusion is complete, the system outputs an enhancement map. This map is added back to the decoded frame from the codec pipeline. The result is the final enhanced video that goes to the display.
This final frame typically shows:
- restored sharpness in text, hair, and patterns
- fewer compression blocks and ringing artifacts
- better perceived resolution
- more natural gradients in skies and skin tones
Importantly, none of this requires sending additional bits over the network. The bitrate stays the same; the intelligence moves to the playback side.
Conclusion
The industry is moving rapidly toward higher resolutions, immersive media, and increasingly sophisticated visual expectations. HEVC, AV1, and VVC continue to evolve, but compression alone cannot fully satisfy the competing demands of quality, cost, and bandwidth.
Amazon’s patent highlights an important strategic direction: enhancing video not only through more aggressive codecs, but through AI-driven post-processing that restores compressed video quality after decoding. This approach directly supports Amazon’s dual identity as both a streaming service operator and a leading cloud provider.
Other companies including Netflix, YouTube, and Nvidia are pursuing related technological paths, but each brings its own architecture and deployment strategy. Amazon’s proposal focuses on multiscale super-resolution, residual learning, and integration into large-scale cloud and delivery systems.
As video pushes deeper into 8K, AR, and VR, and as bandwidth remains finite, approaches like these will likely become standard components of the streaming pipeline rather than experimental add-ons. AI will increasingly sit next to codecs, improving what compression removes, and shaping how the next generation of visual media is delivered.